Graphs are the new black
We all have written some form of a query to retrieve information at some point of our lives. That query indeed will output something we asked it to find, but never anything extra that might be useful. Sure someone would say, google always tells me about the restaurants near a destination I looked up or Amazon usually recommends me a lot more options in shoes when I wish to buy some sneakers. All this extra information that comes with our search can be really useful and it sure doesn’t work on a rigid database but on a much connected Graph Database.
What is Graph database you may ask? Similar to a network of connected nodes, a GraphDb is composed of two elements: a node and a relationship. A node is any object in the network and a relationship (edge) is a connection between that object with other objects in the network.
In the picture below, Person is a node and knows is the relationship between the connected nodes. The Person node can hold unique values like a name to distinguish itself from other person nodes.
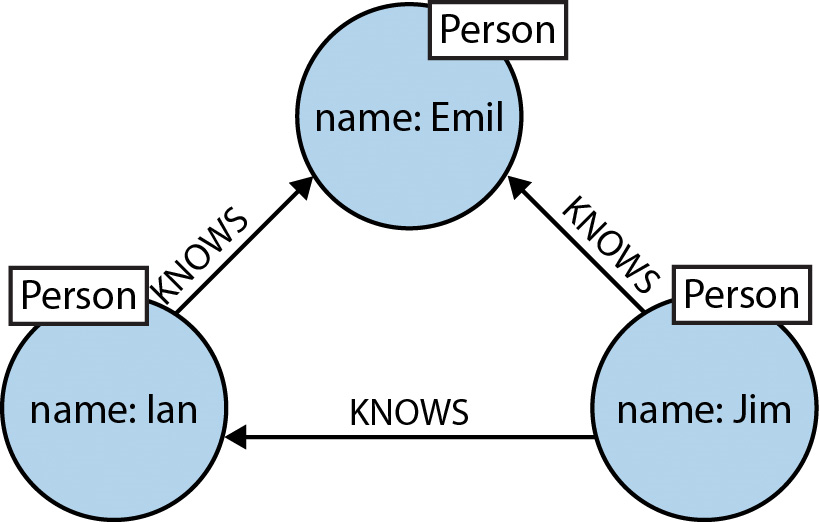
Coming back to why are we talking about GraphDb again? Graph databases are very adept at working with not just single points of information like in case of SQL tables, but also evolving relationship networks. Graphs work particularly well when the relationships inside your data are important and your queries depend on exploring connected nodes and drawing insights by capturing deeper networks.
Whether you want to find out the social connections or inferring relationships based on activity or likes of a person, graph databases offer a plethora of possibility when it comes to creating social networks or integrating current social graphs into an enterprise application for example companies leveraging Twitter data to know their customers better.
All this GraphDB hype is alright but one might be curious about what is wrong with traditional Database systems of rows and columns, I would say plenty of things, especially if you are planning on building a specific model which is heavily dependent on relationship data. Traditional relational databases (your table like Databases), were the powerhouse of software applications and data administration since the ’80s, they still work well when your data is predictable and fits well into tables, columns, rows, and wherever queries are not very join-intensive.
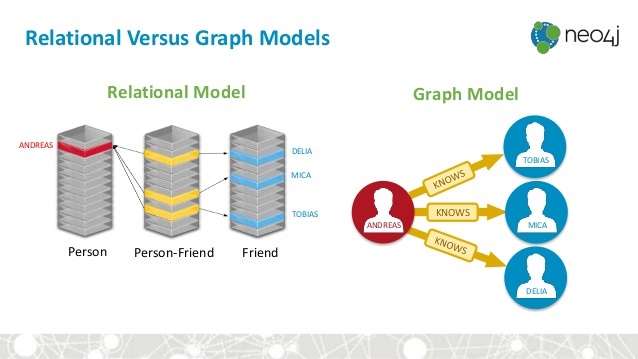
One of the biggest differences between GraphDB and RDb (relational Database) is that the in GraphDb connections between nodes are directly linked, and are an inherent aspect of graphs, in case of RDb you need to explicitly perform a join operation between tables to know about the relationship between two objects.
This allows queries to traverse or hop-over millions of connected nodes per second, offering response times that are several times faster than RDb for connected queries (e.g., friend-of-friend/shortest path). If you are looking for multiple connections and links between object in your application, let’s say a retail vendor wants to know if customers who are based in Canada have bought a product as gift around Christmas, in RDb using SQL queries like this might require JOINs for fetching all those customers, product and transaction information, sometimes 10 joins over millions of rows, this can make data queries really slow.
With a graph database, you find a starting point, traverse in the graph and identify the relevant relationships. For instance, you might write a query that asks, ‘Find all of the friends of the friends of David who watched Wonder Woman last weekend.’ Instead of having to JOIN many different indexes (or tables as they are joined on indexes), the graphDB will use the already created relationships like Friends_with, Watched_movie which would be already present in the network based on activities of David and his friends. Something like on Facebook, what our friends are upto? since Facebook captures likes and posts of our friends.
Now that you are little warmed up with the idea of graphDB, after looking at it’s compelling and ubiquitous applications you might wonder why GraphDb is making its rounds in tech. I have personally worked with graphDB using the most popular GraphDB platform Neo4j and if not this little blog, Neo4j’s documentation can surely convert a pro-RDb to GraphDb-phile?
Today’s CEOs and CTOs don’t just need to manage larger volumes of data – they need to generate insights from their existing data and GraphDb can provide insights and connections on the go.
Almost all social and search tech giants like Google, Facebook, LinkedIn , Glassdoor have moved to graph databases to create successful search and recommendation engines. A graph database is purpose-built to handle highly connected data.
GraphDb finds it’s place in anti-fraud technologies in banks or money transfer platforms like Paypal, Western Union. Traditional anti-fraud technologies use techniques such as a deviation from normal purchasing patterns, which works on discrete data and analysts have to query a SQL Server database to evaluate the customer information as well as extra data from outside vendors who capture phone and IP details in order to find a pattern of fraudulent purchase.
However, today’s savvy fraudsters escape fraud- detection models by forming fraud rings comprised of stolen and synthetic identities. To investigate such fraud rings, it is important to look beyond individual data points to the connections and finding links (relationships) between them.
Here is an image to show a fraud-ring which was identified using Neo4j’s GraphDb
GraphDb can be used to create some of the most powerful recommendation engines by leveraging the power of connections. Several American retailers like Walmart rely on graphDb to build a real-time recommendations engine, and eBay has built a chatbot on top of its internal knowledge graph. Instead of a tabular view of transactions, retail companies can pull together product, customer, inventory, supplier and social sentiment data into a graph database.
Many companies use their customer’s Twitter and Facebook activities to know their likes, dislikes, people they are connected to create custom build offers for their customers.
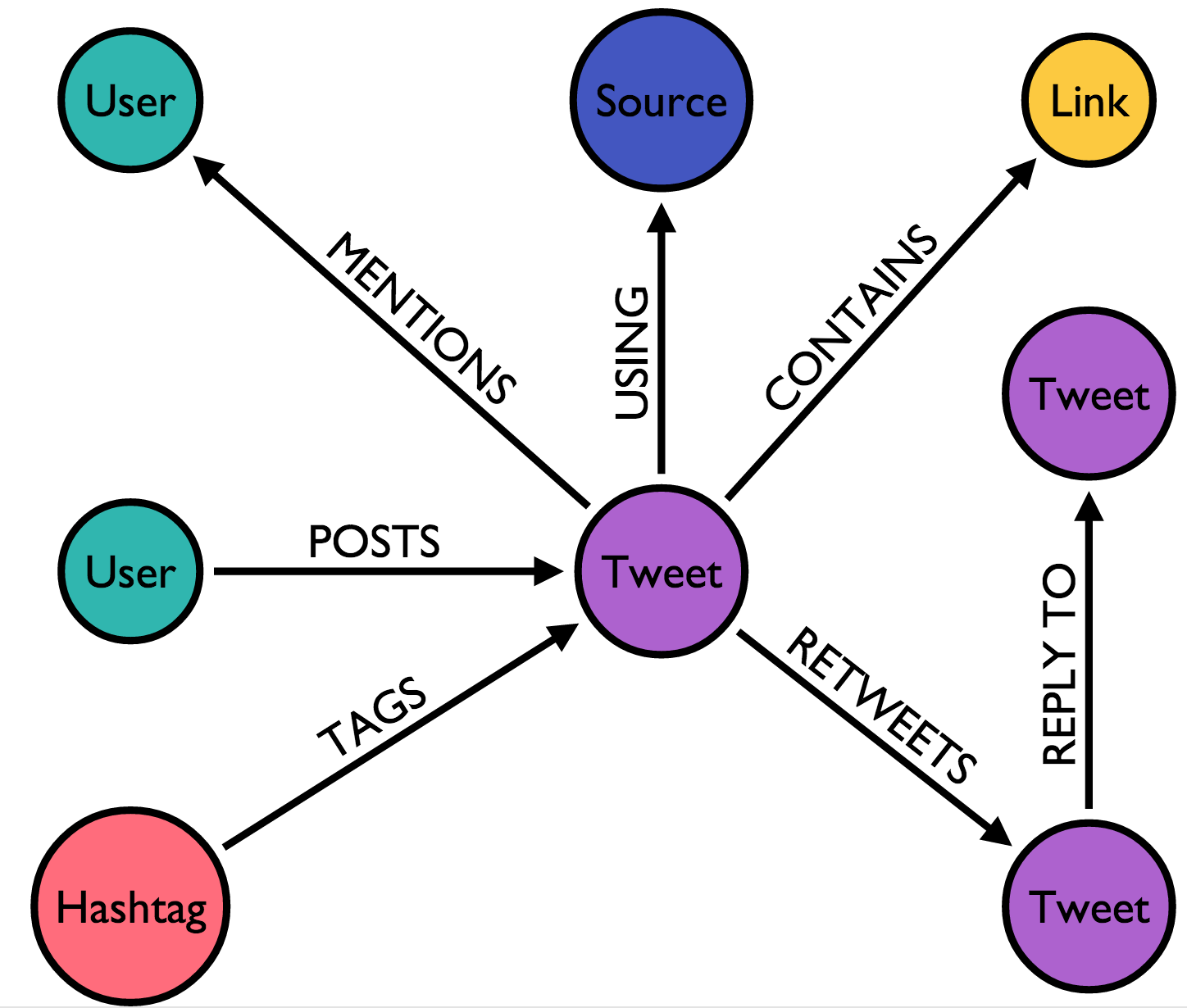
In the end we all want a little extra information, few more recommendations and beautiful visualizations to draw detailed insights from. If you are looking for a application specific way of storing information and querying it lightening fast, GraphDb is the way to go